Byte Latent Transformer: A New Approach to Language Processing#
Let’s understand “Byte Latent Transformer: Patches Scale Better Than Tokens.” This paper introduces a novel approach to handling large language models tokens, potentially offering significant improvements in efficiency and performance. We will explore the core concepts, methodology, and potential implications of this research, drawing insights from the original paper and related discussions.
Unveiling the Byte Latent Transformer#
The paper proposes a significant advancement in the field of natural language processing. The core idea revolves around using byte-level patches instead of traditional word-level tokens for processing text. This approach aims to improve the performance of large language models, particularly in scenarios where memory and computational resources are constrained. The authors argue that using patches allows for a more efficient representation of the input data, leading to faster training and better generalization. Crucially, the paper claims that this approach yields superior results compared to traditional token-based methods, especially as model sizes increase.
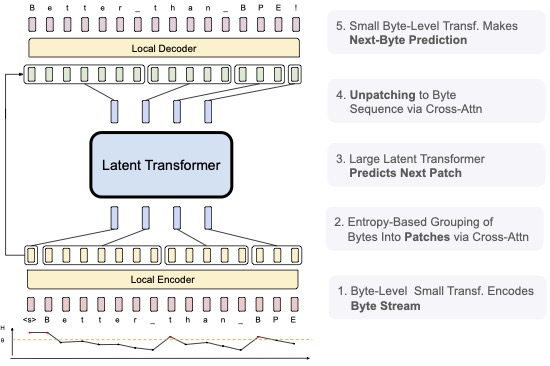
The paper’s methodology focuses on a novel way of representing text data. Instead of dividing text into words or sub-words (tokens), the Byte Latent Transformer breaks down the input into byte-level patches. This approach, the authors claim, allows the model to capture contextual information across larger spans of text, leading to improved performance. The methodology is detailed in the paper, describing how these patches are used in the transformer architecture. This innovative approach could significantly impact how large language models are trained and used.
The paper’s key contribution lies in its demonstration of improved performance with byte-level patches. The authors present empirical evidence, likely through various experiments and comparisons, showcasing how models trained with this technique achieve better results than those using traditional tokenization methods. This is a crucial aspect of the research, as it validates the theoretical claims and provides concrete evidence of the approach’s effectiveness. The results, if accurate, could revolutionize the field of language processing.
Potential Applications and Implications#
The Byte Latent Transformer’s potential applications are vast and span several domains. Improved efficiency in training and deploying large language models could lead to more accessible and affordable natural language processing applications. This is particularly relevant for tasks like machine translation, text summarization, and question answering. The potential impact on these applications could be substantial.
Further, the research could be instrumental in developing more compact and efficient models for resource-constrained environments, such as mobile devices or embedded systems. This opens doors for innovative applications in areas like real-time language processing and personalized language assistance. The potential for real-world applications is significant.
A Promising New Frontier in Language Processing#
The Byte Latent Transformer represents a potentially significant advancement in the field of natural language processing. The paper’s innovative approach, focusing on byte-level patches, promises to improve the efficiency and performance of large language models. The potential implications for various applications, from machine translation to personalized language assistance, are substantial. Further research and development in this area are likely to yield even more exciting advancements in the years to come. This research is a valuable contribution to the field.
Comments
comments powered by Disqus